XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 15 abril 2025

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
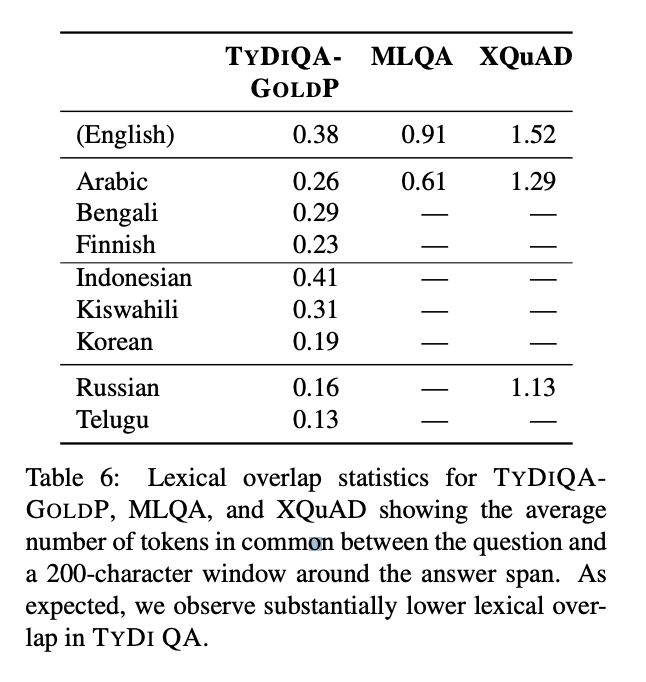
TyDiQA-GoldP Dataset
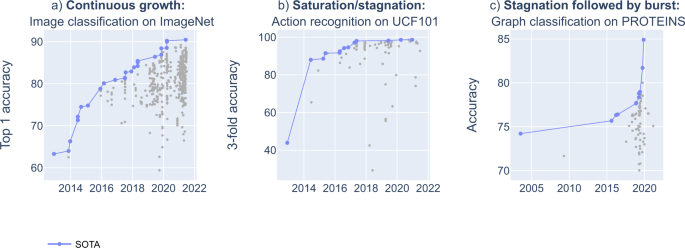
Mapping global dynamics of benchmark creation and saturation in

An example from the SQuAD dataset. Evidences needed for the answer
Introduction of a new dataset and method for location predicting

Sensitivity to parameter choices on the Kazer et al.⁶ dataset and

LSP Dataset - Machine Learning Datasets
Understanding Semantic Search— (Part 1: Introduction to Machine

Sample from the GermanDPR dataset. 0.0 0.2 0.4 0.6 0.8 1.0 0.4 0.5
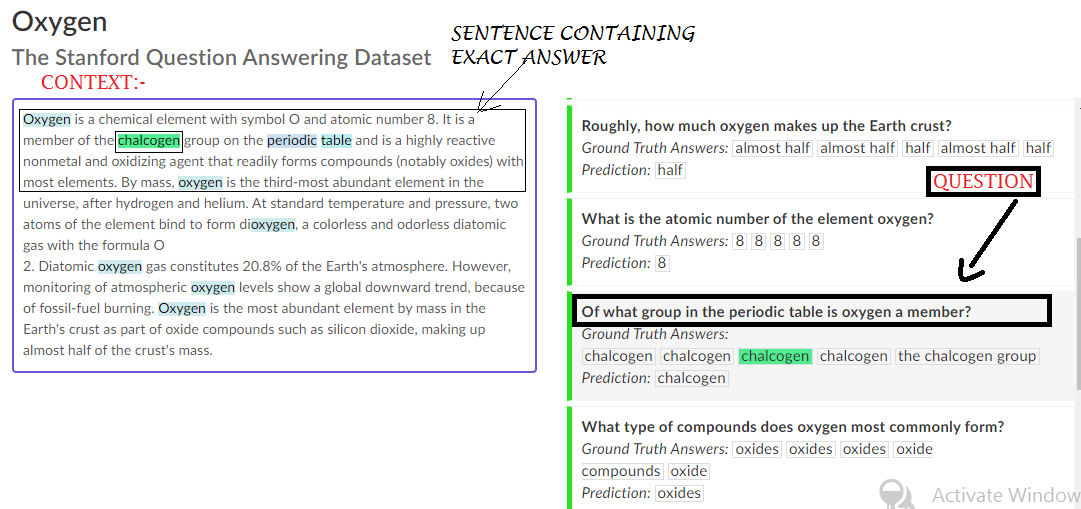
End to End Question-Answering System Using NLP and SQuAD Dataset

Number of questions in the original SQuAD 2.0 dataset and our
GPT-3 and the rise of foundation models
Recomendado para você
-
Internal Combustion Engine Question and Answer, PDF, Internal Combustion Engine15 abril 2025
-
 STCW_Test_-Answers_Report_Management Questions and answers., Exams Health sciences15 abril 2025
STCW_Test_-Answers_Report_Management Questions and answers., Exams Health sciences15 abril 2025 -
![PDF] ME6016 Advanced I.C. Engines (AICE) Books, Lecture Notes, 2marks with answers, Important Part B 16marks Questions, Question Bank & Syllabus – EasyEngineering](https://i0.wp.com/easyengineering.net/wp-content/uploads/2017/07/advance-ic-engines-219x300.jpg?resize=219%2C300) PDF] ME6016 Advanced I.C. Engines (AICE) Books, Lecture Notes, 2marks with answers, Important Part B 16marks Questions, Question Bank & Syllabus – EasyEngineering15 abril 2025
PDF] ME6016 Advanced I.C. Engines (AICE) Books, Lecture Notes, 2marks with answers, Important Part B 16marks Questions, Question Bank & Syllabus – EasyEngineering15 abril 2025 -
 Petrol Engine MCQ, IC Engine MCQ Questions, Petrol Engine vs Diesel Engine15 abril 2025
Petrol Engine MCQ, IC Engine MCQ Questions, Petrol Engine vs Diesel Engine15 abril 2025 -
 Ic engine ies gate ias 20 years question and answers15 abril 2025
Ic engine ies gate ias 20 years question and answers15 abril 2025 -
![Lamb's questions and answers on the marine diesel engine - Stanley G. Christensen [1990, PDF] :: Морской трекер](https://seatracker.ru/i/p/de/72/de729db0cc861b17f1bfe9885abf858a.jpg) Lamb's questions and answers on the marine diesel engine - Stanley G. Christensen [1990, PDF] :: Морской трекер15 abril 2025
Lamb's questions and answers on the marine diesel engine - Stanley G. Christensen [1990, PDF] :: Морской трекер15 abril 2025 -
 PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES15 abril 2025
PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES15 abril 2025 -
 SOLUTION: Mechanical engineering interview questions pdf - Studypool15 abril 2025
SOLUTION: Mechanical engineering interview questions pdf - Studypool15 abril 2025 -
 ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score15 abril 2025
ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score15 abril 2025 -
 NODE.JS Interview Questions & Answers - CodeWithCurious15 abril 2025
NODE.JS Interview Questions & Answers - CodeWithCurious15 abril 2025

você pode gostar
-
 Smarty Bubbles Xmas no Jogos 36015 abril 2025
Smarty Bubbles Xmas no Jogos 36015 abril 2025 -
 Salmence on X: I spent a lot of time on this video. I thought I'd take a dive into all of the weird speedruns I see floating around for Stardew Valley!15 abril 2025
Salmence on X: I spent a lot of time on this video. I thought I'd take a dive into all of the weird speedruns I see floating around for Stardew Valley!15 abril 2025 -
 Kit 10 Cubos Mágicos Atacado e Revenda Profissional Educativo na15 abril 2025
Kit 10 Cubos Mágicos Atacado e Revenda Profissional Educativo na15 abril 2025 -
 TRASH TALK DESTROY HOODIE HOODED SWEATSHIRT NEW OFFICIAL BAND NO PEACE 119 EYES15 abril 2025
TRASH TALK DESTROY HOODIE HOODED SWEATSHIRT NEW OFFICIAL BAND NO PEACE 119 EYES15 abril 2025 -
 Crunchyroll entra com ação contra sites de anime piratas no Brasil - IntoxiAnime15 abril 2025
Crunchyroll entra com ação contra sites de anime piratas no Brasil - IntoxiAnime15 abril 2025 -
 Exit, Germany. 14th July, 2022. firo : July 14th, 2022, football, 1st Bundesliga, season 2022/2023, SC Verl - BVB, Borussia Dortmund Marco REUS, BVB, single action Credit: dpa/Alamy Live News Stock Photo - Alamy15 abril 2025
Exit, Germany. 14th July, 2022. firo : July 14th, 2022, football, 1st Bundesliga, season 2022/2023, SC Verl - BVB, Borussia Dortmund Marco REUS, BVB, single action Credit: dpa/Alamy Live News Stock Photo - Alamy15 abril 2025 -
 Demon Slayer Season 3: All About The Swordsmith Village Arc - Fossbytes15 abril 2025
Demon Slayer Season 3: All About The Swordsmith Village Arc - Fossbytes15 abril 2025 -
 How to Download and Play Roblox on PC-Game Guides-LDPlayer15 abril 2025
How to Download and Play Roblox on PC-Game Guides-LDPlayer15 abril 2025 -
 Os Grandes Jogadores de Xadrez: Mikhail Tal15 abril 2025
Os Grandes Jogadores de Xadrez: Mikhail Tal15 abril 2025 -
DAIENE SERENA BASTOS - FADERGS - Porto Alegre, Rio Grande do Sul, Brasil15 abril 2025
