AlphaZero vs the Drawn Evaluation
Por um escritor misterioso
Last updated 15 abril 2025

It has been clear for a while that AlphaZero is a chess program unlike any other. Armed only with the rules of the game, it played "millions of games against itself via a process of trial and error called reinforcement learning. At first, it plays completely randomly, but over time the system learns

Monte-Carlo Graph Search for AlphaZero – arXiv Vanity

Google's AlphaZero Destroys Stockfish In 100-Game Match

AlphaZero vs AlphaZero

Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess

Training AlphaZero for 700,000 steps. Elo ratings were computed from

AlphaZero/Kramnik: More variants

Understanding AlphaZero Neural Network's SuperHuman Chess Ability - MarkTechPost
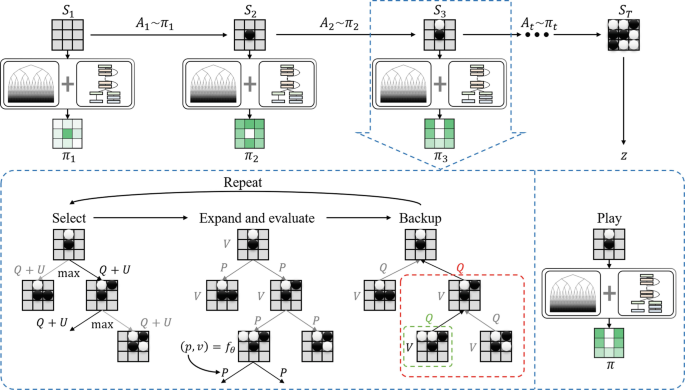
AlphaZero SpringerLink

AlphaZero

Acquisition of chess knowledge in AlphaZero
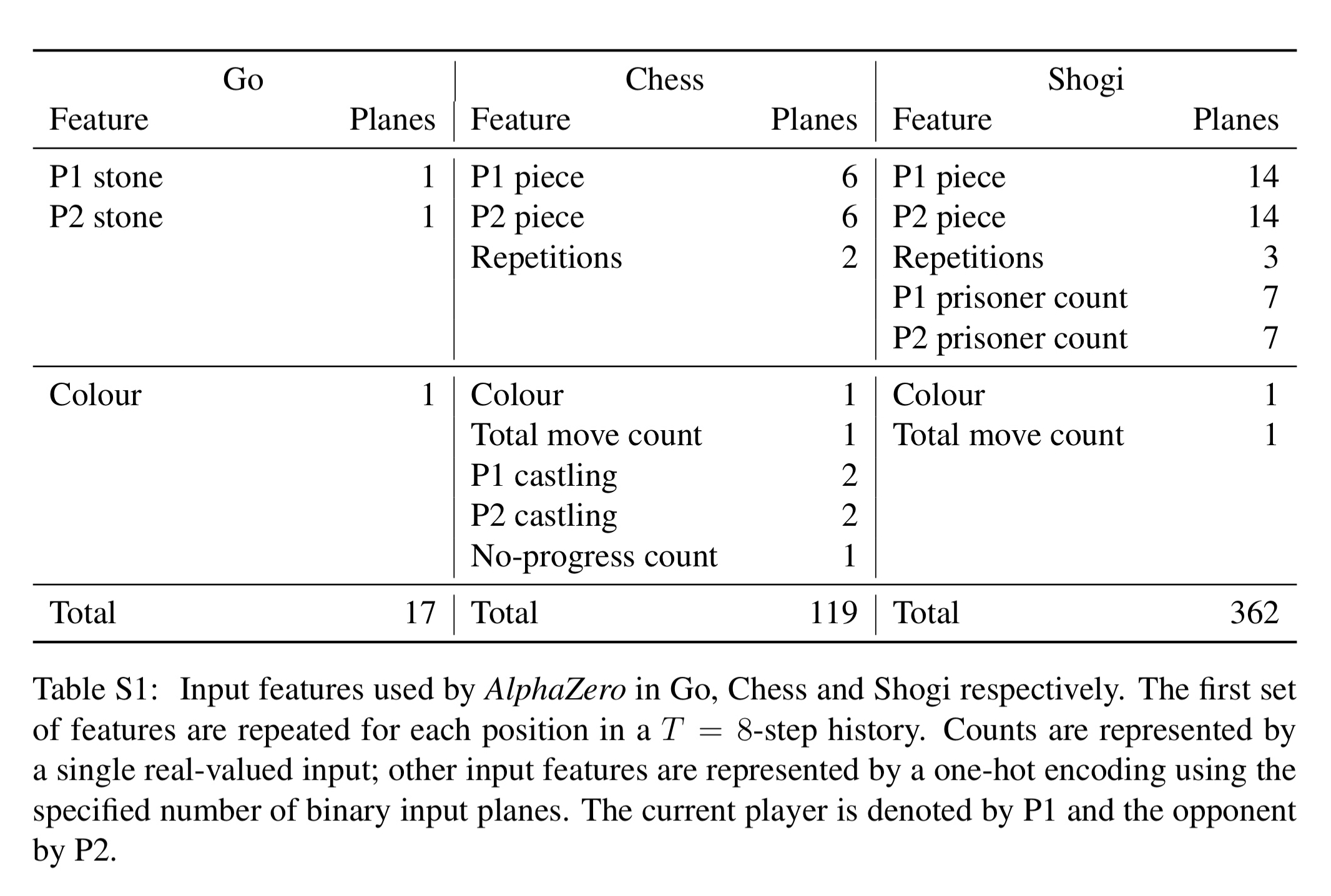
Mastering chess and shogi by self-play with a general reinforcement learning algorithm

AlphaZero paper discussion (Mastering Go, Chess, and Shogi) • Life In 19x19
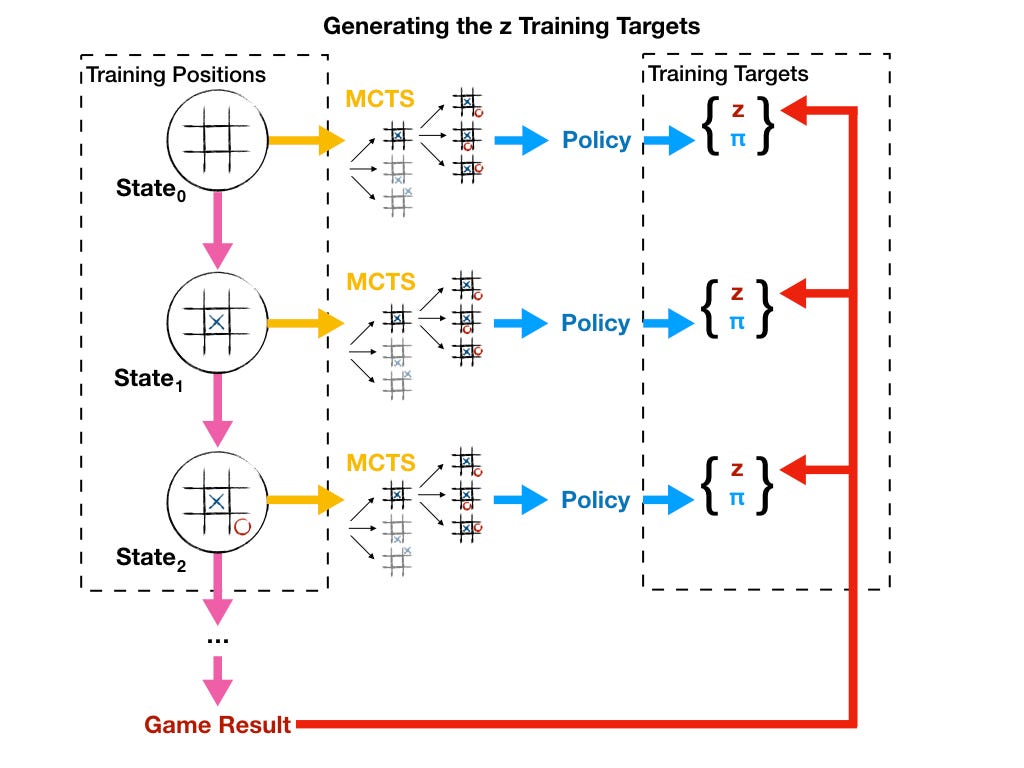
Lessons From AlphaZero (part 4): Improving the Training Target, by Vish (Ishaya) Abrams, Oracle Developers

Are Self-Learning Game Players Truly Intelligent?, by Dave Whipp
Recomendado para você
-
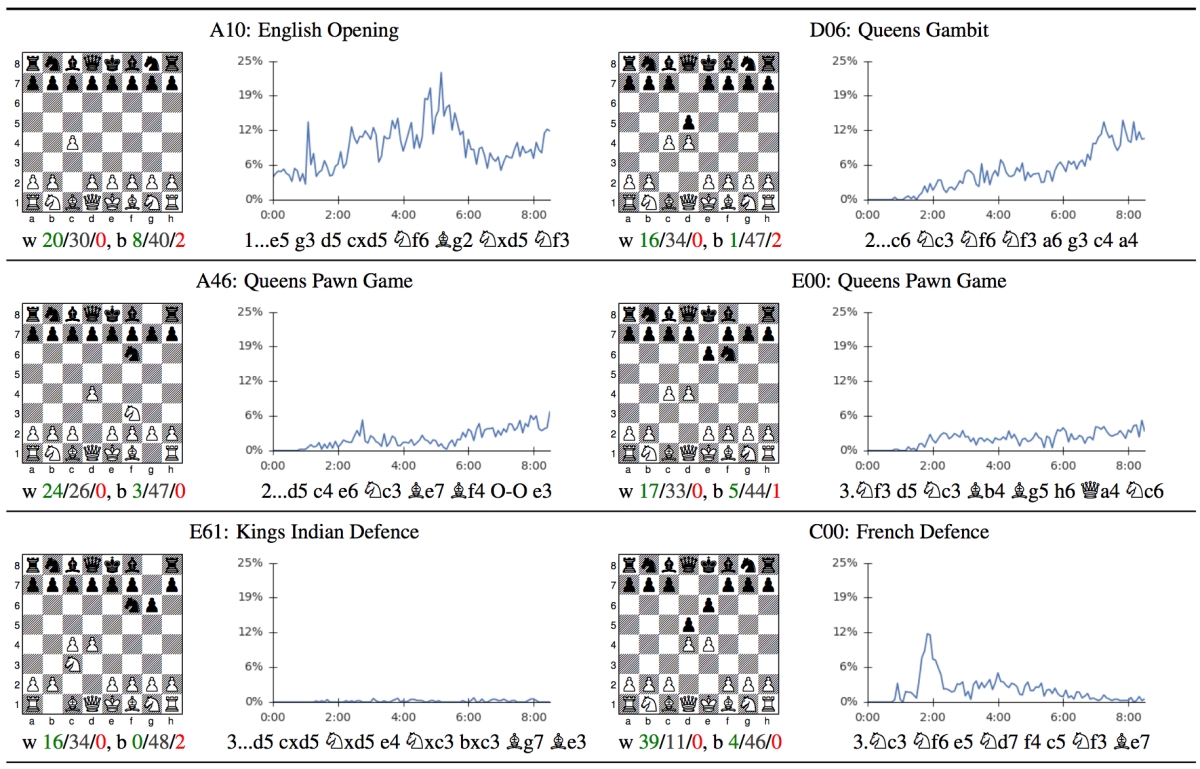
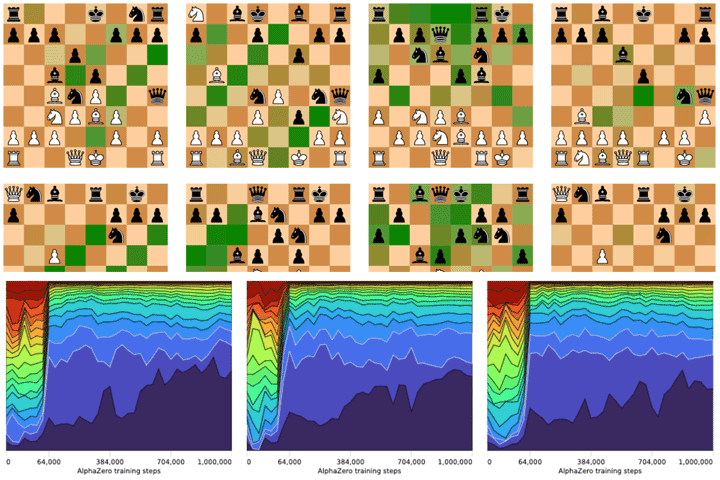 Acquisition of Chess Knowledge in AlphaZero15 abril 2025
Acquisition of Chess Knowledge in AlphaZero15 abril 2025 -
 AlphaZero on Carlsen-Caruana Games 1-815 abril 2025
AlphaZero on Carlsen-Caruana Games 1-815 abril 2025 -
 PLAY-CHESS-ALPHAZERO - Play Chess with Friends15 abril 2025
PLAY-CHESS-ALPHAZERO - Play Chess with Friends15 abril 2025 -
 Deepmind's AlphaZero Plays Chess15 abril 2025
Deepmind's AlphaZero Plays Chess15 abril 2025 -
 The Rise of Chess AI: From Deep Blue to AlphaZero15 abril 2025
The Rise of Chess AI: From Deep Blue to AlphaZero15 abril 2025 -
 AlphaZero: Its Great Predecessors15 abril 2025
AlphaZero: Its Great Predecessors15 abril 2025 -
 Kasparov Exclusive: His MasterClass, St. Louis, AlphaZero15 abril 2025
Kasparov Exclusive: His MasterClass, St. Louis, AlphaZero15 abril 2025 -
 AlphaZero beat humans at Chess and StarCraft, now it's working with quantum computers15 abril 2025
AlphaZero beat humans at Chess and StarCraft, now it's working with quantum computers15 abril 2025 -
 When Alphazero Plays with himself !, Alphazero vs Alphazero, Levy15 abril 2025
When Alphazero Plays with himself !, Alphazero vs Alphazero, Levy15 abril 2025 -
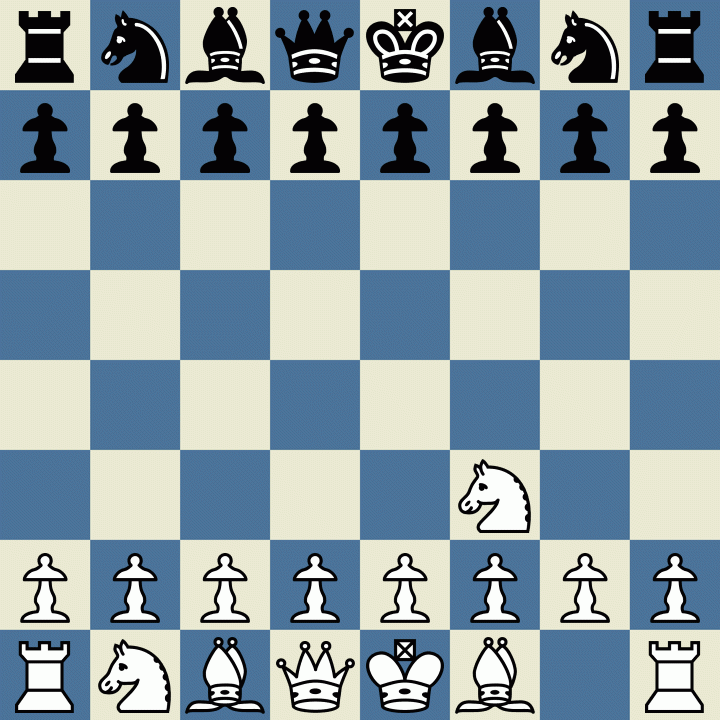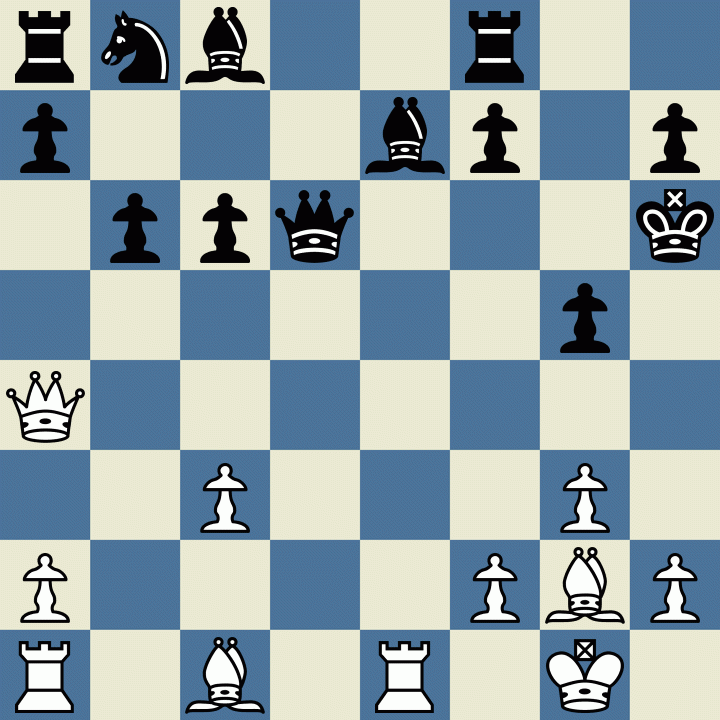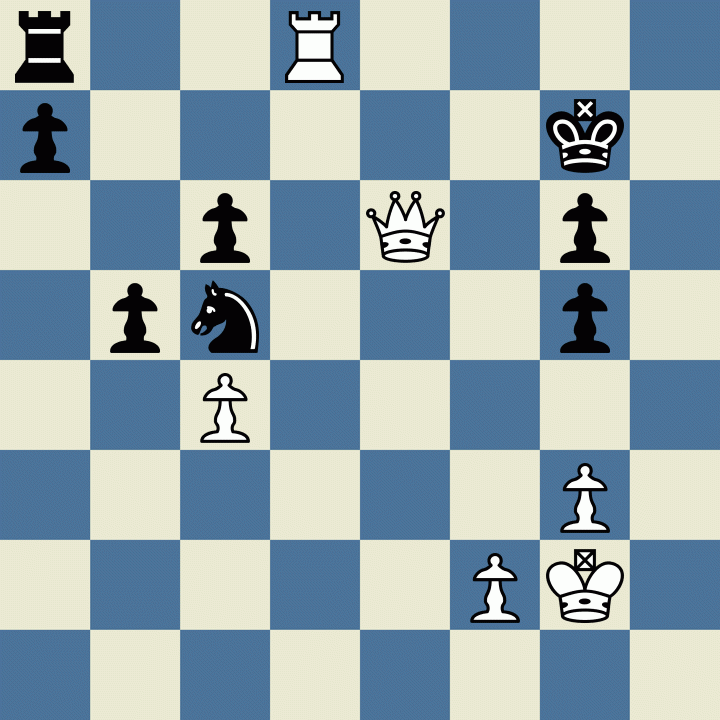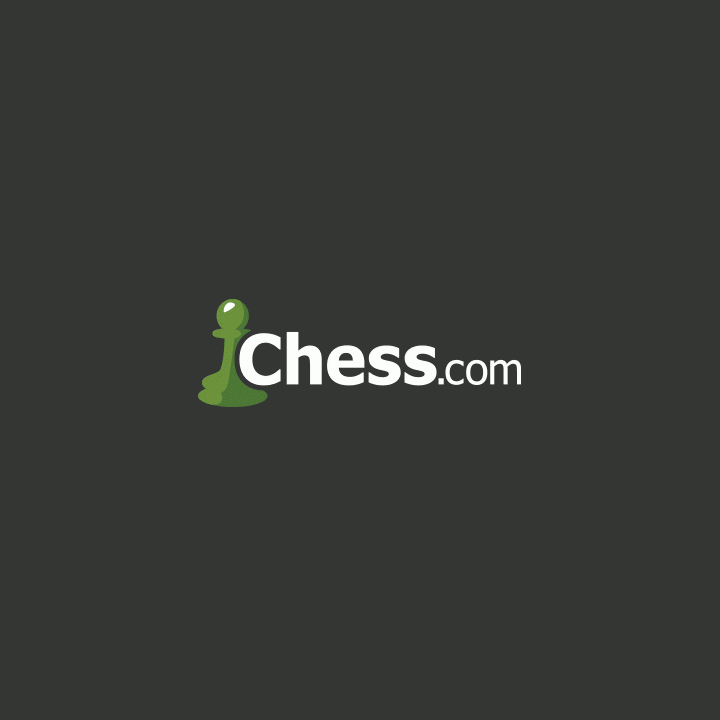 AlphaZero 1-0 Stockfish - How the Fish Fell to the Zero - Chess Forums15 abril 2025
AlphaZero 1-0 Stockfish - How the Fish Fell to the Zero - Chess Forums15 abril 2025
você pode gostar
-
 Evil Dead: The Game Review – A Little Rough Around the Edges15 abril 2025
Evil Dead: The Game Review – A Little Rough Around the Edges15 abril 2025 -
 Trading these for Halloween pets this year (2023) everything is15 abril 2025
Trading these for Halloween pets this year (2023) everything is15 abril 2025 -
 Empresa de Turismo Palusa 5005 em Assis por Marcelo Costa - ID:1729858 - Ônibus Brasil15 abril 2025
Empresa de Turismo Palusa 5005 em Assis por Marcelo Costa - ID:1729858 - Ônibus Brasil15 abril 2025 -
Slenderman,Slendrina:The Cellar 2,Slendrina:The School,Slendrina,Slendrina:The Forest, Ador Player15 abril 2025
-
 Messy Munching Mouse Alliteration, Messy, Lesson plans15 abril 2025
Messy Munching Mouse Alliteration, Messy, Lesson plans15 abril 2025 -
 Score (x38-) in 25:06.217 by Natcat - Subway Surfers - Speedrun15 abril 2025
Score (x38-) in 25:06.217 by Natcat - Subway Surfers - Speedrun15 abril 2025 -
 Just Dance 2024 está disponível nos consoles; veja as músicas - Adrenaline15 abril 2025
Just Dance 2024 está disponível nos consoles; veja as músicas - Adrenaline15 abril 2025 -
 Crítica Halloween 2 - O Pesadelo Continua (1981): consolidando o mito - Cinema com Rapadura15 abril 2025
Crítica Halloween 2 - O Pesadelo Continua (1981): consolidando o mito - Cinema com Rapadura15 abril 2025 -
dragon ball z kai intro|TikTok Search15 abril 2025
-
 6 Ways to Add a Chill Vibe to Your Room - Society1915 abril 2025
6 Ways to Add a Chill Vibe to Your Room - Society1915 abril 2025